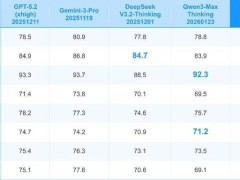
春節前夕,科技圈迎來重磅消息:阿里巴巴正式發布新一代開源大模型Qwen3.5-Plus,在參數規模縮減的情況下實現性能躍升,引發行業廣泛關注。這款被視為"春節科技彩蛋"的模型,以3970億參數刷新了人們對大模型發展的認知——其參數量僅為前代旗艦Qwen3-Max的40%,卻達到了與谷歌Gemini 3 Pro相當的性能水平。
最令人矚目的是其極致的效率優化:每次響應僅激活170億參數,相當于僅調用5%的算力資源就能實現滿血性能。這種"四兩撥千斤"的技術突破,直接將用戶調用成本壓低至Gemini 3 Pro的1/18。阿里云智能集團研究員透露,這得益于全新引入的混合注意力機制,使模型能夠像人類閱讀般"有詳有略"地處理信息,在保證核心精度的同時大幅降低計算開銷。
回顧Qwen系列的發展軌跡,堪稱一部持續自我顛覆的技術進化史。從1.5版本啟動細粒度專家模式,到3.0版本摒棄沿用三代的共享專家架構改用路由專家,再到此次3.5版本引入混合注意力,每個重大升級都伴隨著對既有技術路線的徹底革新。這種"革自己命"的勇氣,使Qwen系列始終保持著開源領域的領跑地位——其每次發布幾乎都會登頂開源模型排行榜,成為行業技術演進的重要風向標。
支撐這次突破的底層技術,源自阿里在2025 NeurIPS全球AI頂會上斬獲最佳論文的門控機制創新。這項被命名為"Dynamic Gate"的技術,通過動態調整專家模塊的參與度,實現了參數利用效率的質變。更值得關注的是,阿里選擇將這項核心成果完全開源,所有科技企業均可直接應用于自身模型優化,展現出中國科技公司推動行業共同進步的開放姿態。
在多模態能力建設上,Qwen3.5展現出驚人的發展速度。該模型從預訓練階段就采用文本-視覺混合數據聯合學習,使視覺與語言處理在統一參數空間內深度融合。這種設計使其天然具備跨模態理解能力,無需像傳統模型那樣通過后期微調實現模態對齊。測試數據顯示,其在圖文理解、視頻分析等任務上的表現已超越多數專用模型,為構建通用人工智能(AGI)奠定了重要基礎。
隨著Qwen3.5的發布,中國開源模型陣營已形成完整的技術矩陣:Qwen主打全能基座,GLM專注長文本處理,Kimi強化推理能力,DeepSeek深耕垂直領域。這種差異化競爭與協同創新的格局,使中國開源模型在技術指標、應用場景、生態建設等維度實現對閉源模型的全面包圍。有行業分析師指出,當前國產大模型與全球頂尖水平的差距已從6個月縮短至3個月,技術迭代速度呈現明顯的加速趨勢。
這場由開源驅動的技術革命,正在重塑全球AI競爭格局。阿里巴巴用實際行動證明:在AI時代,真正的領先不在于技術封鎖,而在于通過持續創新為行業提供基礎設施。正如阿里AI實驗室負責人所言:"我們追求的不是某個模型的短暫領先,而是通過開源構建一個讓所有開發者都能受益的技術生態。"這種開放共贏的理念,或許正是中國AI產業實現彎道超車的關鍵密碼。