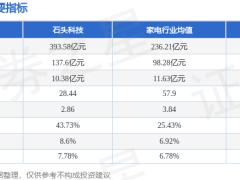
程序員們常調侃,最痛苦的時刻不是熬夜寫新代碼,而是凌晨被叫醒修復自己幾個月前埋下的“神級Bug”。但如今,meta公司的一項新研究讓AI不僅能自己制造問題,還能在無人指導的情況下通過“自我對弈”的方式解決問題,這一突破引發了科技界的廣泛關注。
12月下旬,meta與伊利諾伊大學厄巴納-香檳分校聯合發表的論文,詳細介紹了一種名為SSR(Self-play SWE-RL)的全新系統。該系統的核心思路看似簡單卻充滿顛覆性:讓同一個大語言模型同時扮演“破壞者”和“修復者”的角色。傳統AI編程工具,如GitHub Copilot,依賴人類編寫的代碼、修復過的Bug以及設計的測試用例進行學習,相當于“做老師布置的題目”。而SSR則完全反其道而行之,讓AI自己出題、自己解答。
具體實現上,SSR將一個模型拆分為兩個智能體:一個負責向開源項目中注入隱蔽的Bug,另一個則需根據有限線索找出并修復這些錯誤。兩個角色共享參數,本質上是同一個“大腦”,卻執行著完全相反的任務。這種設計類似于一個人用左手制造問題,再用右手解決問題,且全程不能參考答案。
為了確保生成的Bug質量,SSR引入了三重驗證機制:首先,Bug必須能被弱化測試檢測到;其次,不能直接暴露修復路徑;最后,需通過“逆向變異測試”確認改動確實改變了程序行為。無效的Bug會被直接丟棄,絕不摻雜水分。這種機制生成的訓練數據,質量遠超人工標注,因為所有Bug均源自真實的Git歷史記錄,例如故意撤銷某次修復提交或刪除看似冗余實則關鍵的邏輯。這些案例并非教科書中的典型問題,而是工程實踐中常見的“暗坑”。
在實戰測試中,SSR的表現令人矚目。研究團隊在SWE-bench Verified和SWE-bench Pro兩個基準平臺上進行了評估。這兩個平臺由普林斯頓、斯坦福等機構共同構建,收錄了來自Django、PyTorch等知名項目的真實Bug修復任務,被視為衡量AI編程能力的“試金石”。實驗結果顯示,即使完全屏蔽人類提供的任務描述和測試用例,SSR訓練的智能體性能仍持續提升,最終超越了采用傳統強化學習加人類數據訓練的基線模型。而后者在訓練幾十輪后便陷入停滯,難以進一步突破。
進一步的分析揭示了SSR成功的關鍵:消融實驗表明,若僅訓練Bug注入智能體,模型會陷入“只會搞破壞”的困境;若僅提供固定Bug集讓AI修復,模型則會迅速過擬合。只有讓兩個智能體形成閉環聯動,動態調整任務難度,才能持續產生新挑戰,促使模型不斷進步。這種機制類似于健身時自動增加重量,始終保持“跳一跳夠得著”的狀態。
盡管SSR展現了強大的潛力,但其局限性同樣明顯。研究團隊在論文中坦承,首先,系統嚴重依賴單元測試作為評判標準,但現實開發中許多問題(如性能瓶頸、安全漏洞、用戶體驗)無法通過測試腳本量化;其次,目前兩個智能體使用同一模型架構,尚未探索“強弱對抗”(如用更大模型充當出題者)是否更有效;最后,訓練過程極不穩定,嘗試加入自然語言描述或聚焦單一代碼倉庫時,性能反而下降。這些限制表明,SSR距離“全自動程序員”仍有很大差距。
不過,SSR的意義遠不止于技術突破。它標志著AI正在從“模仿人類”轉向“自我創造學習信號”。就像AlphaGo走出人類從未想過的棋路,SSR也可能發現工程師忽略的缺陷模式或修復策略。事實上,12月下旬,智譜AI發布了“伐謀”智能體框架,支持多智能體協同演化;阿里通義實驗室也宣布Qwen Code Agent進入企業內測階段。全球頂尖團隊紛紛押注“自主進化型AI”,而SSR的獨特之處在于,它幾乎不需要人類監督。