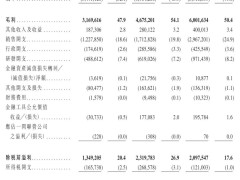
智能手機拍照時自動識別場景中的物體,AI繪畫工具根據文字描述生成藝術作品——這些日常應用背后,隱藏著一個困擾人工智能領域多年的核心矛盾:視覺理解與圖像生成需要完全不同的技術路徑。前者如同精密顯微鏡,需捕捉語義層面的抽象信息;后者則像工筆畫師,必須精確控制每個像素的細節。這種矛盾長期制約著AI視覺系統的整體發展,直到一支跨國研究團隊提出突破性解決方案。
由清華大學、華中科技大學與快手科技Kolors團隊聯合研發的VQRAE技術,在2025年11月發表的論文中首次實現了視覺理解與生成任務的統一架構。這項被比喻為"雙焦眼鏡"的創新技術,使AI系統能夠同時具備兩種核心能力:既能像文學評論家般分析圖像內涵,又能如數字藝術家般創作全新畫面。研究團隊通過純Vision Transformer架構與高維語義量化技術,成功訓練出利用率達100%的編碼本,包含16384個1536維的"視覺詞匯",徹底顛覆了傳統向量量化方法的設計范式。
技術突破的核心在于創造性的雙階段訓練策略。第一階段凍結預訓練視覺基礎模型,專注訓練量化模塊與對稱解碼器,確保語義理解能力不受影響;第二階段解凍整個編碼器,通過自蒸餾機制維持原有特征提取能力,同時優化圖像重建質量。這種漸進式訓練方式不僅解決了統一架構中的任務沖突問題,更使系統在ImageNet-50k驗證集上取得1.31的rFID分數、22.23的PSNR值和0.762的SSIM值,超越多數傳統方法。
實驗數據顯示,VQRAE在多模態理解任務中展現出驚人實力。在MME-Perception、SEED-Bench等標準測試集上,該技術達到與專用理解模型相當甚至更優的性能,且無需額外訓練——僅需替換現有模型的視覺編碼器即可實現性能提升。在視覺生成任務中,0.6B參數的輕量級模型在Geneval和DPG-Bench基準上達到與更大規模模型相當的水平,證明高質量離散表示對自回歸生成的關鍵作用。
研究團隊通過消融實驗揭示了多項關鍵發現:編碼本維度需達到1536維才能避免訓練崩潰,16384個條目構成最佳平衡點;自蒸餾約束的權重設置直接影響語義理解與生成質量的平衡;純ViT架構在視覺重建任務中展現出超越卷積網絡的潛力。這些發現為未來統一視覺模型的設計提供了重要指導原則,特別是在高維語義特征處理與訓練策略優化方面。
技術實現細節處處體現精妙設計:采用SigLIP2-so400m和InternViT-300M等預訓練模型作為基礎,解碼器使用與編碼器完全對稱的ViT結構;量化過程引入SimVQ方法提升靈活性;損失函數融合重建損失、感知損失與對抗損失;數據增強策略避免破壞語義信息。這些設計共同確保了系統在復雜場景下的穩定表現,特別是在處理人物肖像、自然風景等多樣化視覺內容時展現出強大泛化能力。
實際應用場景已顯現清晰輪廓。內容創作領域將誕生新一代智能助手,能夠同時理解用戶意圖并生成高質量圖像;教育系統可基于學生理解水平動態生成個性化視覺教材;醫療影像分析有望實現病理識別與標準化對比圖像生成的統一處理;游戲引擎將具備實時生成新場景與角色的能力。參與研究的快手科技透露,相關技術已進入產品化驗證階段,預計1-2年內面向普通用戶推出。
盡管當前技術在處理文字密集圖像或高細節區域時仍存在局限,但研究團隊通過聚類分析驗證了系統表示質量:連續語義特征聚焦語義相似性,離散標記關注紋理細節,這種分化特性正是統一架構的理想狀態。隨著模型規模擴大與訓練數據積累,這些邊界問題有望逐步解決。該成果不僅為構建通用人工智能奠定基礎,更預示著AI工具將向更智能、更靈活的方向進化,最終成為能夠適應多元需求的智能伙伴。