在新加坡人工智能發展進程中,一項重要合作引發全球關注。阿里云與新加坡國家人工智能計劃(AISG)攜手,共同帶來重大成果:新加坡最新國家級大語言模型“海獅”(Sea - Lion v4),摒棄了此前采用的美國技術路線,轉而全面基于阿里的通義千問Qwen3 - 32B開源模型構建。
這一合作成果意義非凡,是在全球AI競爭格局下的又一重要突破。此前,硅谷知名人士Chamath Palihapitiya宣布用Kimi取代OpenAI作為生產力工具,美國Vercel、Windsurf等編程平臺接入智譜模型,愛彼迎CEO稱阿里Qwen比美國模型更好用,而此次新加坡國家人工智能計劃的認可,進一步證明中國開源模型在全球市場不斷拓展影響力。在“主權AI”和“多語言適配”領域,中國開源大模型已展現出替代甚至超越硅谷巨頭的潛力。
回顧過往,2023年12月,新加坡啟動了一項價值7000萬新元(約5200萬美元)的計劃,旨在提升多模態大型語言模型(LLM)的研究和工程能力,其中就包括開發Sea - Lion(東南亞語言一體化網絡)。然而,東南亞這片擁有6億人口、數字經濟規模向萬億美元邁進的市場,長期以來卻是西方AI的“盲區”。
數據匱乏是首要問題。在Sea - Lion誕生之前,meta Llama 2等主流模型中,東南亞語言內容占比僅0.5%。這種以英語為中心的訓練邏輯,讓以Llama2訓練的早期Sea - Lion模型出現嚴重問題。在測試中,該模型竟將南美洲的委內瑞拉列為東盟成員國,這種缺乏區域常識的“幻覺”,暴露出西方通用模型在本地化應用上的巨大短板。
語言文化隔閡也給當地開發者帶來諸多困擾。東南亞地區盛行“語碼轉換”,即在英語中夾雜方言,像新加坡式英語(Singlish)或馬來西亞式英語(Manglish)。面對這種復雜的混合語境,標準的美式AI模型往往難以理解其中的細微差別和文化梗。
而且,Llama雖在開源模型中性能領先,但“英語中心主義”的基因難以改變,處理泰語、緬甸語等非拉丁語系文字時效率極低。AISG逐漸意識到,使用硅谷開源模型并非東南亞國家的最佳選擇,他們需要的是真正懂多語言、懂亞洲語境的模型底座。
于是,在發布v4版本時,AISG將目光投向中國,選用阿里的Qwen3 - 32B作為新一代Sea - Lion的基座模型。與西方模型不同,Qwen3的基礎模型在預訓練階段就通過36萬億個token的數據訓練,覆蓋全球119種語言和方言。這種“原生多語言能力”使Qwen不僅“懂”印尼語、馬來語,還能從底層邏輯理解這些語言的語法結構,大大降低了AISG后續訓練的難度。
為解決東南亞語言獨特的書寫習慣問題,Qwen - Sea - Lion - v4摒棄西方模型常用的“句子分詞器”,采用更先進的字節對編碼(BPE)分詞器。鑒于泰語、緬甸語等語言通常沒有明顯詞間空格,BPE技術能更精準切分非拉丁語系字符,不僅提高翻譯準確度,還大幅提升推理速度。
商業落地現實考量也是阿里勝出的關鍵因素。東南亞有大量中小企業,無力承擔昂貴的H100 GPU集群。Qwen - Sea - Lion - v4經過優化,可在配備32GB內存的消費級筆記本電腦上流暢運行。這意味著普通印尼開發者僅憑一臺高配電腦就能在本地部署這個國家級模型,這種“工業級能力,民用級門檻”的特性,精準切中了該地區算力資源稀缺的痛點。
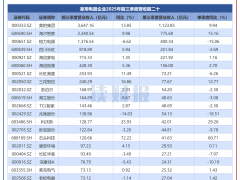
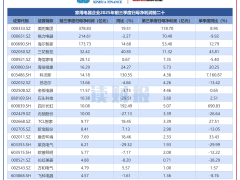
此次合作并非簡單的“單向技術輸出”,而是深度雙向融合。根據協議,阿里提供強大通用推理底座,AISG則貢獻珍貴的、經過清洗的1000億個東南亞語言token。這些數據無版權風險,且東南亞內容濃度高達13%,是Llama2的26倍。阿里運用“高級后訓練”技術,將這些區域知識注入Qwen,使其能精準捕捉當地文化神韻。效果立竿見影,在Sea - Helm評估榜單上,搭載阿里“心臟”的Sea - Lionv4迅速在同量級開源模型中占據榜首。
從新加坡Sea - Lion項目從AWS轉向阿里云,從Llama轉向Qwen的演變,可以看出全球AI格局正發生微妙變化。長期以來,全球技術基礎設施幾乎被美國壟斷。但在大模型時代,中國企業憑借對多語言環境的深刻理解和極致的性價比優化,正成為“全球南方”國家構建主權AI的首選合作伙伴。